


Množstvá dát, ktoré sú dnes dostupné na internete, nie sú štruktúrované, a tak s nimi treba pracovať veľmi citlivo. Na túto problematiku sa pozrel študent bratislavského gymnázia Miroslav Cibuľa. Vytvoril platformu na vyhľadávanie dát s užitočnými vyhľadávacími technikami. So svojím projektom sa zúčastnil na Festivale vedy a techniky AMAVET, a tak sme ho oslovili na rozhovor

Na webe je pre nás dostupných čoraz viac informácií, ktoré sú kedykoľvek k dispozícii. Zdá sa, že to je výhoda, ale nemusí to tak byť. Prečo?
Najväčší problém spočíva práve vo vyhľadávaní konkrétnych informácií vo veľkej mase dát. Prehľadať veľké množstvo informácií nachádzajúcich sa na internete za krátky čas je možné len pomocou rôznych počítačových algoritmov. Drvivá väčšina informácií uložených na internete nie je štruktúrovaná. Sú ukryté v texte, ktorý však nie je strojovo čitateľný, takže klasické algoritmy z nedokážu neho vyberať konkrétne kúsky informácií.
Podľa vás je zatiaľ najbežnejšou metódou využitie klasických webových prehliadačov. Ako dnes pracujú rôzne vyhľadávacie nástroje?
Existujú klasické/ konvenčné, napríklad Google, vyhľadávače špecializujúce sa na rôzne štruktúrované informácie, ktoré sú ukladané v databázach a napokon experimentálne, ktoré sa snažia priamo odpovedať na otázky používateľov.
Klasické vyhľadávače fungujú v niekoľkých krokoch. Najprv prehľadávajú celý web a mapujú ho v podstate do siete stránok, keďže každá stránka odkazuje na inú stránku. Na získanej sieti stránok sa ďalej vykonáva indexovanie, keď sa v skratke každá stránka spracováva a vyberajú sa z nej rôzne údaje. V poslednom kroku, pri ktorom používateľ zadáva požiadavku do vyhľadávača, sa stránky na základe informácií získaných pri indexovaní hodnotia podľa relevantnosti k zadanej požiadavke a zoradený zoznam stránok sa zobrazuje.
Vyhľadávače špecializujúce sa na odpovedanie na otázky ale fungujú na inom princípe.
Áno a rozdelil by som ich do dvoch kategórií. Prvou je odpovedanie na otázky na základe informácií (z angl. information-retrieval-based question answering). Sem spadajú algoritmy, ktoré sú schopné v podstate čítať s porozumením dlhé texty a následne odpovedajú na otázky tým, že v texte označia slovo alebo časť, ktorá odpovedá na otázku. Toto sa realizuje prostredníctvom umelej inteligencie, ktorá je špecificky naučená na vykonávanie tejto úlohy.
Druhou metódou je odpovedanie na otázky založené na vedomostiach ( z angl. knowledge-based question answering). Do tejto kategórie spadajú algoritmy, ktoré odpovedajú na otázky pomocou štruktúrovaných informácií v obrovských databázach. Keď používateľ zadá otázku, inteligentné algoritmy sa ju snažia preložiť na strojovú databázovú požiadavku, ktorú následne vyhľadávajú vo svojich databázach.
Vy ste sa rozhodli vytvoriť platformu, vďaka ktorej bude vyhľadávanie jednoduchšie. Ako táto platforma funguje?
V podstate ide o webový vyhľadávač, tak ako Google, ktorý však zahŕňa viacero vyhľadávacích techník na čo najrýchlejší a najefektívnejší prístup k informáciám.
Primárne je vyhľadávač konštruovaný tak, aby dokázal odpovedať priamo na otázky. To robí buď čítaním webových dokumentov, ktorých zoznam získava prostredníctvom klasického webového vyhľadávania, a vyberaním odpovedí z nich, alebo získavaním informácií z niekoľkých webových databáz. Čiže kombinuje dve metódy odpovedania na otázky.
Vyhľadávač tiež poskytuje klasické webové vyhľadávanie, ktoré je dostupné aj v prípade, že nie je možné odpovedať na otázky, takže stále tam nejaká vyhľadávacia funkcionalita je. Tiež sa vo vyhľadávači nachádza aj sumarizačný panel, ktorý zhŕňa fakty o vyhľadávanom objekte. Celá architektúra tohto systému je navyše navrhnutá modulárne, čo znamená, že každý prvok tohto systému je nezávislý od ostatných a dokáže sa jednoducho napojiť do vyhľadávača, čím by svojimi funkciami mohol rozširovať schopnosti tohto systému. Takýto dizajn dáva potom priestor komukoľvek, kto vie programovať, aby prispel do systému nejakou funkcionalitou.
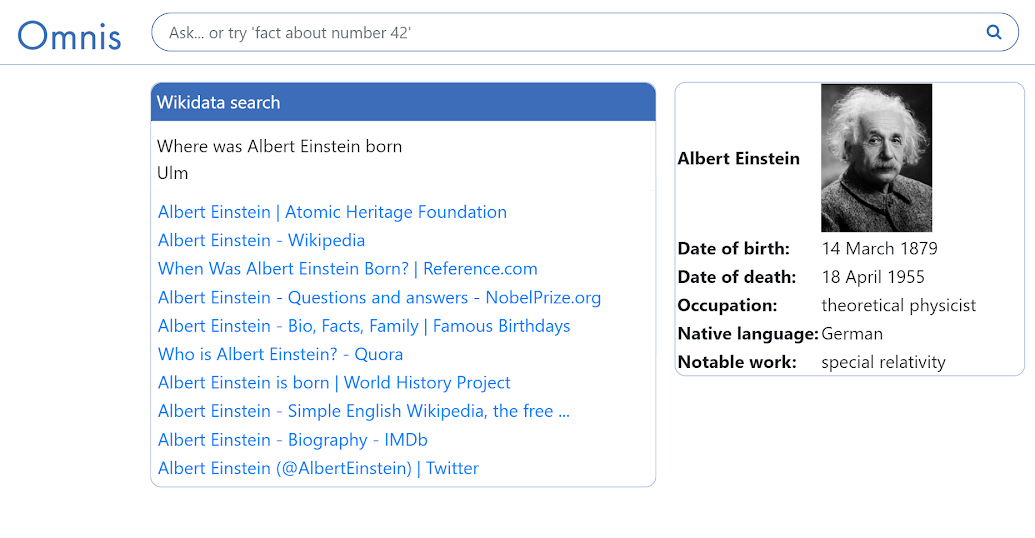
Vyhľadávač Omnis, ktorý vytvoril Miroslav Cibuľa
V rámci svojej práce ste vytvorili niekoľko modelov, ktoré sú schopné napríklad overovať emailové adresy, generovať fakty o číslach, premieňať jednotky alebo generovať texty piesní. Ako raz toto všetko ľuďom „brázdiacim“ po internete môže pomôcť?
Pokiaľ bude tento systém rozširovaný rôznymi modulmi, mohol by nahradiť klasické vyhľadávače a urýchliť a zjednodušiť prístup k informáciám. Okrem toho by mohol zhŕňať rôzne nástroje a programy vo forme modulov, čím by sa jeho využitie stalo v podstate neobmedzené.
Ako sa k tomuto vášmu produktu dostanú bežní užívatelia?
Je dostupný ako webová stránka na adrese omnisqa.com, avšak zatiaľ existuje len vo forme prototypu, ktorý nie je pripravený na produkčnú prevádzku.
Takže na projekte treba ešte výrazne popracovať. Kedy asi odhadujete, že by sa mohol dostať do praxe?
Rád by som si s touto platformou založil startup, aby som ho vedel spolu s ďalšími ľuďmi dostať do konkurencieschopného stavu a ďalej rozvíjať. Chcem pri tom využiť aj svoje vedomosti z robotiky, chémie a fyziky, ktorým sa venujem popri počítačovej vede a umelej inteligencii.


